 İnce Satırlar
İnce Satırlar Liste Modu
Liste Modu Döşeme Modu
Döşeme Modu Sade Döşeme Modu
Sade Döşeme Modu Blog Modu
Blog Modu Hibrit Modu
Hibrit Modu
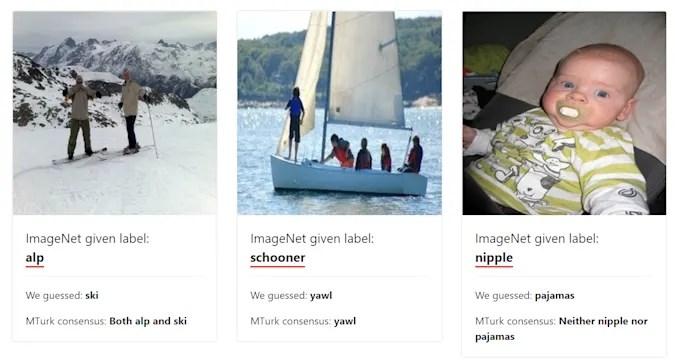
MIT araştırmacıları makine öğrenimi sistemlerini test etmek için kullanılan on veri setini mercek altına aldı. Bilgisayar bilimcileri öncülüğündeki ekip, verilerin yaklaşık yüzde 3.4'ünün hatalı veya yanlış etiketlendiğini ve bu veri setlerini kullanan yapay zeka (AI) sistemlerinde sorunlara neden olabileceklerini tespit ettiler.
Her biri 100.000'den fazla alıntılanan veri kümeleri arasında haber grupları, Amazon ve IMDb gibi metin tabanlı olanlar da var. Amazon ürün değerlendirmelerinin, aslında olumlu olmasına rağmen olumsuz olarak (veya tam tersi) yanlış etiketlenmesi gibi hatalar göze çarpıyor.
Görüntü tabanlı hatalar ise hayvan türlerinin karıştırılması ile ortaya çıkıyor. Ayrıca fotoğrafların daha az göze çarpan nesne merekezinde yanlış etiketlenmesi de söz konusu. Örneğin dağ bisikleti yerine su şişesi etiketinin kullanılması.
Ciddi sorunlara yol açabilir
YouTube videolarındaki sesleri temel alan bir başka veri kümesi üç buçuk dakika boyunca kamerayla konuşan bir YouTuber'ın görüntüsünü yalnızca son 30 saniye içinde duyulabilmesine rağmen "kilise çanı" olarak etiketliyor. Bruce Springsteen performansının "orkestra" olarak sınıflandırılması da bir başka hata olarak dikkat çekiyor.
Yapay zeka ve makine öğrenimi alanı, birçoğu halka açık veri kümelerinin bir alt kümesinden gelen verileri kullanarak sonuca varmak üzere inşa edilmiştir. Etiketlerin hatalı olması, makine öğrenimi sistemleri için ciddi sıkıntılara yol açabilir. Araştırmacılar herkesin söz konusu hatalara göz atabilmesi için bir web sitesi de kurmuş durumda.
Bu haberi ve diğer DH içeriklerini, gelişmiş mobil uygulamamızı kullanarak görüntüleyin:








