 İnce Satırlar
İnce Satırlar Liste Modu
Liste Modu Döşeme Modu
Döşeme Modu Sade Döşeme Modu
Sade Döşeme Modu Blog Modu
Blog Modu Hibrit Modu
Hibrit Modu
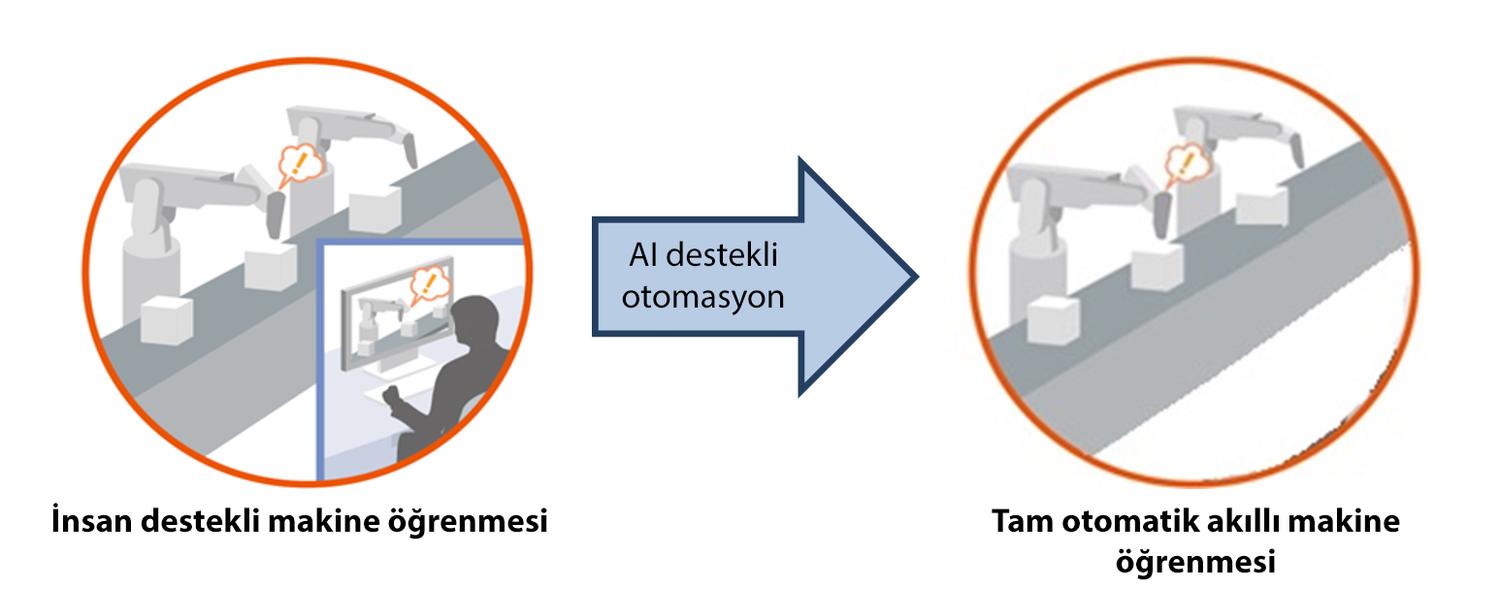
İnsan destekli makine öğrenmesi sağlayan mevcut teknolojilerde birkaç saat ile yarım gün arasında değişen optimizasyon süreci, Mitsubishi Electric'in derin pekiştirmeyle öğrenme (deep reinforcement learning) yöntemi kullanan tam otomatik akıllı makine öğrenme algoritması sayesinde birkaç dakika'dan 30 dakikaya kadar değişen kısa bir zamana iniyor.
Yapay zeka alanında günden güne hızla ilerleme kaydedilse de makinelerin öğrenmesi için gerekli denemelerin sayısının çok fazla olması ve bir yardımcıya ihtiyaç duyulması bu ilerlemeleri yavaşlatan bir unsur olarak karşımıza çıkıyor. DRL (deep reinforcement learging) algoritması ile makinelerin öğrenme süreci için sensör ve kamera verilerini kullanarak derin pekiştirmeyle öğrenme yöntemi uygulanacak.
Derin Pekiştirmeyle Öğrenme Yöntemi Nasıl Çalışıyor?
DRL, makineye verilen ödül ve cezalar ile öğrenim işleminin daha hızlı sonuçlanmasını sağlıyor. Makine, bir doğru yaptığı zaman ödül puanı bir arttırılıyor. Aynı şekilde bir yanlış yaptığı zaman da yanlış puanı bir azaltılıyor. Makine, bir koşul ile karşılaştığında ödül puanını yüksek tutabilmek için en olması gereken çözümü uyguluyor. Buna ek olarak doğru ve yanlış puan katsayıları, koşulun önemine göre belirlenebiliyor. Sonuç olarak makine, öğrenme işlemine başladığı zaman doğruluğu en yüksek seviyede tutmaya çalışırken olası büyük hatalardan kaçınıyor. İki yanlış seçenek arasında kaldığı zaman ise sonucunun en az hata doğuracağı seçeneği seçiyor.
DRL yöntemini bir labirent örneği üzerinde anlatalım. Amaç çıkışa ulaşmak ve tek bir çıkışımız olsun. Makine çıkışın neresi olduğunu bilirken hangi yolun çıkışa ulaştığını bilmeyecek. Bir R matrisi ile olası yollar hesaplanır. Bir Q matrisi oluşturulup olası yolların çıkışa olan yakınlığı hesaplanır ve yollara doğruluk dereceleri verilir. İşlemler sonucunda makine, doğruluk puanı en yüksek olan yolu tercih edecektir.

Yapay Zeka Teknolojisini Maisart Markası Altında Sunacak
Mitsubishi Electric kompakt yapay zeka, derin öğrenme algoritması ve akıllı öğrenme uygulamalarını içeren yapay zeka teknolojilerini yeni markası Maisart çatısı altında topluyor. Maisart markası ile cihazları daha akıllı, hayatı daha güvenli, sezgisel ve konforlu hale getirmek amaçlanıyor.
istediğiniz zaman (çevrim dışı bile) okuyabilirsiniz:










1 Kişi Okuyor (0 Üye, 1 Misafir) 1 Masaüstü GENEL İSTATİSTİKLER
3427 kez okundu.
10 kişi, toplam 10 yorum yazdı.
HABERİN ETİKETLERİ
Yapay Zeka, derin öğrenme ve