 İnce Satırlar
İnce Satırlar Liste Modu
Liste Modu Döşeme Modu
Döşeme Modu Sade Döşeme Modu
Sade Döşeme Modu Blog Modu
Blog Modu Hibrit Modu
Hibrit Modu

İngiliz matematikçi ve bilgisayar bilimcisi Alan Turing, Turing testini ilk olarak 1950 yılında "The Imitation Game" ismiyle ortaya koymuştu. O zamandan bu yana, bir makinenin insan konuşmasını taklit etme yeteneğini belirlemek için ünlü ancak tartışmalı bir kriter haline geldi. Testin modern versiyonlarında, bir insan yargıç tipik olarak hangisinin hangisi olduğunu bilmeden ya başka bir insanla ya da bir sohbet robotuyla konuşuyor. Eğer yargıç sohbet robotunu insandan belirli bir oranda güvenilir bir şekilde ayıramazsa, sohbet robotunun testi geçtiği söylenir. Testi geçme eşiği özneldir, bu nedenle geçme başarı oranını neyin oluşturacağı konusunda hiçbir zaman geniş bir fikir birliği olmadı.
ChatGPT, ELIZA'ya yenildi

Site aracılığıyla, insan sorgucular ya diğer insanları ya da yukarıda bahsedilen GPT-4, GPT-3.5 ve 1960'lardan kalma kural tabanlı bir konuşma programı olan ELIZA'yı içeren yapay zeka modellerini temsil eden çeşitli "yapay zeka tanıkları" ile etkileşime girdi. Teste katılan herkese rastgele roller atandı. Testte tanıklara sorgucuyu insan olduklarına ikna etmeleri talimatı verildi. Yapay zeka modelleriyle eşleşen oyuncular ise her zaman sorgucu rolündeydi.
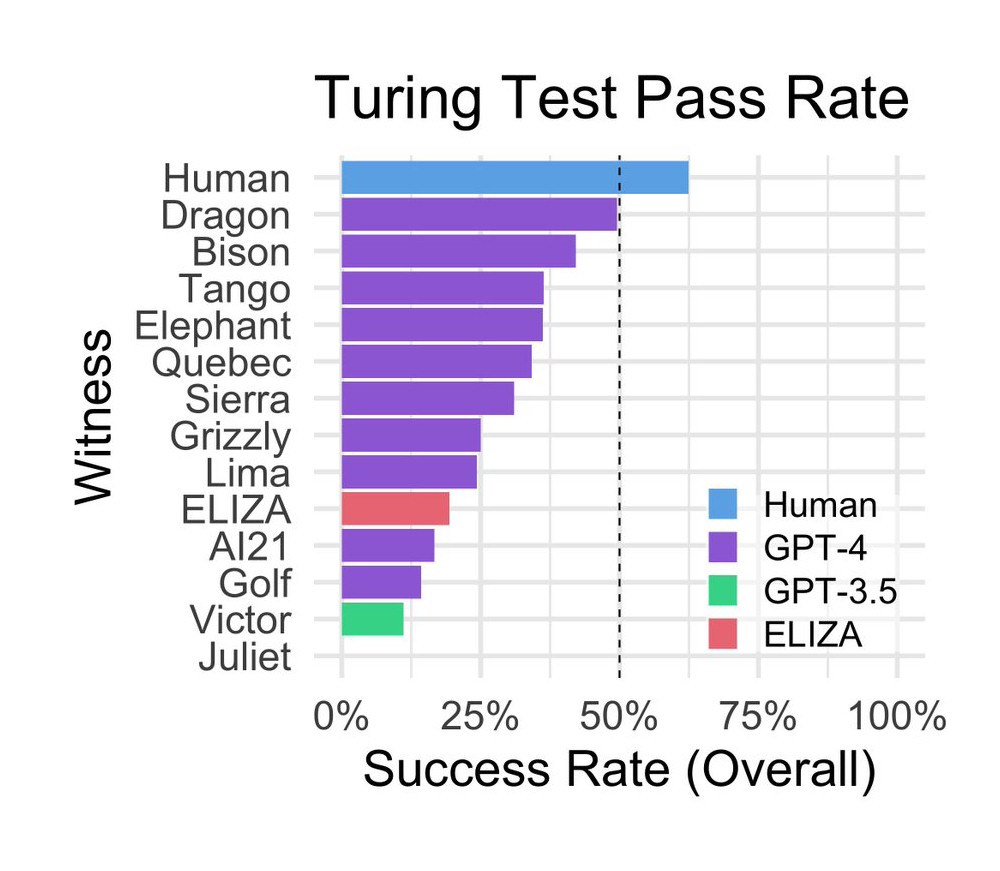
Deneyde 652 katılımcının toplam 1.810 oturum tamamladığı ve bunlardan 1.405 oyunun da analiz edildiği belirtiliyor. Şaşırtıcı bir şekilde, 1960'ların ortalarında MIT'de bilgisayar bilimcisi Joseph Weizenbaum tarafından geliştirilen ELIZA, çalışma sırasında yüzde 27'lik bir başarı oranı elde ederek nispeten iyi bir puan aldı. GPT-3.5, soruya bağlı olarak, ELIZA'nın gerisinde kalarak yüzde 14'lük bir başarı oranı elde etti. GPT-4 yüzde 41'lik bir başarı oranına ulaşarak gerçek insanlardan sonra ikinci sırada yer aldı.
Oturumlar sırasında sıkça kullanılan stratejiler arasında küçük sohbetler ve sorgulamalar yer alıyordu. Dilsel üslup ve sosyo-duygusal özelliklere dayalı olarak yapılan değerlendirmeler, katılımcıların kararlarını şekillendirmekte etkili olmuş gibi görünüyor. Ek olarak çalışma, eğitim seviyesi ve dil modellerine aşinalığın yapay zeka tespitinde belirleyici olmadığını gösteriyor.
GPT-4 de başarısız
Sonuç olarak, çalışmanın yazarları GPT-4'ün Turing testinin başarı kriterlerini karşılamadığı, ne yüzde 50 başarı oranına ulaştığı (50/50 şanstan daha yüksek) ne de insan katılımcıların başarı oranını aştığı sonucuna vardı.
Araştırmacılar, doğru uyarı tasarımıyla GPT-4 veya benzer modellerin sonunda Turing testini geçebileceğini düşünüyor. Ancak asıl zorluk, insan konuşma tarzlarının inceliklerini taklit eden bir ipucu tasarlamakta yatıyor. GPT-3.5 gibi GPT-4 de kendini insan gibi göstermemeye şartlandırılmış durumda.
Öte yandan yapılan oturumlarda insanlar, karşılarında gerçek bir insan olmasına rağmen onların gerçek olduğuna ikna olmadı veya başka bir deyişle; insanlar, insan olduklarını kanıtlayamadı. Bu durum insan zekasının yapısından ziyade testin doğası ve yapısı ile jüri üyelerinin beklentilerini yansıtıyor olabilir. Araştırmacılar bazı insanların yapay zeka gibi davranarak “trolleme” yaptıklarını da belirtiyor.
Bu haberi ve diğer DH içeriklerini, gelişmiş mobil uygulamamızı kullanarak görüntüleyin:







